Definition of Data Stack
Data Stack refers to the collection of technologies, tools, and processes that an organization uses to manage and analyze its data. It encompasses the entire ecosystem of data-related components that work together to ingest, store, process, analyze, and visualize data. The data stack typically includes a combination of databases, data warehouses, data lakes, data processing engines, analytics tools, and more.
As technology evolves, the components and layers within a data stack may change, reflecting advancements in data management and analytics. The data stack plays a crucial role in enabling organizations to derive valuable insights from their data, make data-driven decisions, and support various business functions.
The evolution of the data stack is often discussed in the context of different generations, such as the transition from traditional data warehouses to the emergence of data lakes and, more recently, the development of data lakehouses. Each generation introduces new capabilities and addresses challenges associated with the management and analysis of increasingly large and diverse datasets.
In this blog we would be talking about evolution of different generations of technology stack, pros and cons of each generation.
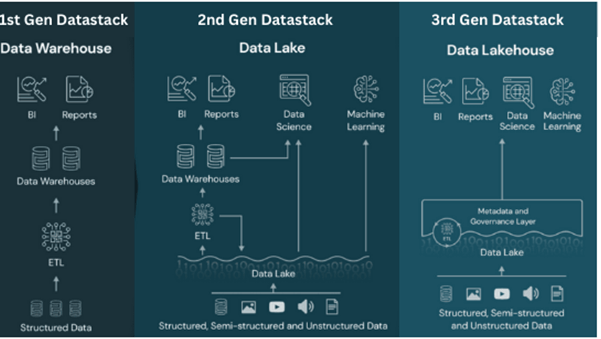
First Generation: Data Warehouses
A data warehouse is a centralized repository of integrated and structured data from various sources within an organization. It is designed to support business intelligence (BI) and reporting activities by providing a unified and consistent view of data. The data in a data warehouse is typically cleaned, transformed, and organized in a way that facilitates analysis and reporting.

Data Warehouse Features:
- Integration: Data from different operational systems and sources are integrated into the warehouse, creating a cohesive and unified dataset. This integration is essential for providing a comprehensive view of the organization’s data.
- Subject-Oriented: Data in a data warehouse is organized around specific subject areas or themes that are relevant to the business, such as sales, finance, or customer relations. This subject-oriented structure makes it easier for users to focus on specific areas of interest.
- Time-Variant: A data warehouse often includes historical data, allowing users to analyze changes and trends over time. This time-variant aspect is crucial for tracking and understanding the evolution of business metrics.
- Non-volatile: Data in a data warehouse is relatively stable and does not change frequently. Once data is loaded into the warehouse, it is typically not updated in real-time, ensuring consistency for reporting and analysis purposes.
- Query and Reporting Tools: Data warehouses are equipped with tools and interfaces that allow users to query, analyze, and generate reports based on the integrated data. There are tools like Open source BI Helical Insight which supports pixel perfect paginated canned reports as well as dashboards.
Limitations of Data Warehouse:
While data warehouses offer valuable benefits for business intelligence and decision-making, they also come with certain limitations. Understanding these limitations is crucial for organizations to make informed decisions about their data management strategies. Here are some common limitations of data warehouses:
- Data Integration Challenges: Integrating data from diverse sources with varying structures and formats can be complex and time-consuming. This also brings the challenges for data quality which can lead to incorrect reporting and analysis at the BI level. There are ETL (extract transform load) tools which are also quite technical and require special expertise to implement to do the entire transformation and loading into the DW.
- Scalability Issues: Scaling a data warehouse to handle large volumes of data can be expensive, both in terms of hardware and software licensing costs.As data volumes increase, query performance may degrade, impacting the responsiveness of the data warehouse.
Further in a data warehouse compute and storage was the same, hence hardware cost was really high equal to the peak users requirement and this kept on growing only. - Data Latency: Traditional data warehouses often rely on batch processing, meaning that data is loaded periodically. This can result in latency, making real-time or near-real-time analysis challenging.
- Limited Support for Unstructured Data: Data warehouses are typically designed for structured data. Handling unstructured or semi-structured data, such as text or multimedia content, may require additional processing steps.
- Rigidity in Schema Design: Altering the schema of a data warehouse can be complex and time-consuming. This rigidity makes it challenging to adapt quickly to additional requirements.
- Cost & Time of Implementation and Maintenance: Implementing a data warehouse involves a significant upfront investment in terms of hardware, software, and time as well from qualified resources.Continuous maintenance, updates, and performance tuning contribute to the total cost of ownership. This is where open source technology stack like open source BI Helical Insight is helpful in bringing down the cost of the ownership.
- Security and Privacy Concerns: Managing the security of sensitive data within a data warehouse is critical. Ensuring proper access controls and data encryption can be challenging.
- User Dependency: Extracting meaningful insights from a data warehouse often requires technical expertise. Business users may depend on IT or data specialists for complex queries and analysis. Though there are self service BI tools like Open Source BI Helical Insight which can still empower end users to drag drop and create reports and other analysis by themselves.
Keeping these drawbacks in mind, data lake came into picture which addresses many of these challenges.
Second Generation Data Stack: Data Lakes
A data lake is a centralized repository that allows organizations to store vast amounts of raw and unstructured data in its native format until it is needed (in many cases in format like CSV, Apache Parquet, ORC etc). Unlike traditional databases or data warehouses that impose a structured schema on the data before it is ingested, a data lake allows for the storage of diverse data types, including raw text, images, videos, and more, without predefined organization.
Also, unlike DW where computer and storage is the same causing increase in cost, here they are different.

Features of Data Lake:
- Storage of Raw Data: Data lakes store data in its raw and unprocessed form, preserving the original structure and format. This includes both structured and unstructured data.
- Scalability: Data lakes are designed to scale horizontally, allowing organizations to store and process massive volumes of data efficiently. This scalability is essential for handling the ever-growing amounts of data generated by businesses.
- Flexibility: Data lakes provide flexibility in terms of data types and schema-on-read rather than schema-on-write. Users can decide how to structure and organize the data at the time of analysis, providing more agility in extracting insights.
- Cost-Effective Storage: By leveraging cost-effective storage solutions, such as cloud-based object storage, data lakes can accommodate large volumes of data at a lower cost compared to traditional storage solutions.
- Support for Big Data Technologies: Data lakes often integrate with big data processing technologies, such as Apache Hadoop and Apache Spark, allowing organizations to perform distributed processing and analytics on large datasets.
- Analytics and Exploration: Data lakes enable data scientists, analysts, and other users to explore and analyze data without predefined structures. This exploratory nature supports a wide range of analytics, including machine learning and advanced analytics.
- Integration with Data Processing Tools: Data lakes can be integrated with various data processing tools, allowing organizations to transform, clean, and analyze data as needed. This integration facilitates the preparation of data for downstream analytics.
Limitations of Data Lake:
While data lakes provide flexibility and scalability, they also come with challenges that organizations need to address to ensure the successful management and utilization of the stored data. Here are some common challenges associated with data lakes:
- Data Governance: Managing metadata is crucial for understanding and cataloging the vast amount of data within a data lake. Inadequate metadata can lead to difficulties in data discovery and interpretation.Also ensuring the quality of data within a data lake is challenging, as it often stores raw and uncurated data. Poor data quality can impact the reliability of analytics and decision-making.
- Data Security and Access Control: Implementing and maintaining proper access controls to sensitive data within a data lake is crucial for preventing unauthorized access and ensuring data privacy. Protecting data at rest and in transit through encryption is essential for maintaining the confidentiality and integrity of stored information.
- Data Lake Architecture Complexity: Designing and implementing an effective data lake architecture can be complex. Decisions related to storage formats, data partitioning, and indexing can impact the performance and usability of the data lake.
- Data Lifecycle Management: Determining how long to retain data in the data lake and when to archive or delete it requires careful consideration. Without proper data lifecycle management, the data lake can become a repository of obsolete or redundant information.
- Data Silos and Integration: Data lakes, if not managed properly, can lead to the creation of data silos, hindering the goal of a unified view of the data. Integrating data from diverse sources while maintaining consistency can be challenging.Integrating data from the data lake with other systems and tools requires careful planning to avoid inconsistencies and ensure data interoperability.
- Complexity in Analysis and Querying: As the volume of data in the data lake grows, query performance can become a challenge. Users may experience delays in retrieving and analyzing data, especially if the data is not properly indexed or organized.
- Data Swamp Risk: If not properly managed, a data lake can turn into a “data swamp,” where the volume of unorganized and low-quality data makes it difficult for users to find and use meaningful information.
These kind of limitations have triggered the development of Modern data stack or 3rd Generation Data Stack.
3rd Gen or Modern Data Stack: Data Lakehouse
A data lakehouse is a hybrid data architecture that combines elements of both data lakes and data warehouses. It aims to address the limitations and challenges associated with each while offering a unified platform for storing, processing, and analyzing diverse types of data. The term “data lakehouse” has gained prominence in response to the evolving needs of organizations dealing with large and varied datasets.
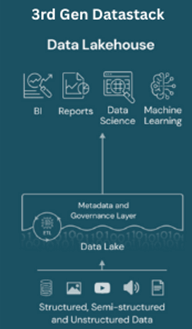
Features of Data Lakehouse:
- Unified Storage: Data lakehouse provides a unified storage layer that accommodates both raw, unstructured data (similar to a data lake) and structured, processed data (akin to a data warehouse). This allows organizations to maintain the flexibility of a data lake while supporting efficient analytics on structured data.
- Schema-on-Read and Schema-on-Write: Like a data lake, a data lakehouse supports schema-on-read, allowing users to apply a schema when data is queried, enabling flexibility. However, it also supports schema-on-write for structured data, ensuring better performance for analytical queries.
- ACID Transactions: A data lakehouse often incorporates features like ACID (Atomicity, Consistency, Isolation, Durability) transactions, which are common in traditional relational databases. This enhances data reliability and consistency, critical for maintaining the quality of structured data.
- Compatibility with Data Warehouses: Data lakehouses are designed to be compatible with existing data warehouses, allowing organizations to leverage their investments in data warehousing technology and seamlessly integrate with their analytics and business intelligence tools.
- Improved Performance: By integrating features from data warehouses, a data lakehouse can offer improved performance for structured data queries compared to traditional data lakes. This makes it more suitable for analytics use cases where quick response times are crucial.
- Support for Multiple Workloads: Data lakehouses are built to support a variety of workloads, including batch processing, real-time analytics, and machine learning. This versatility allows organizations to derive insights from their data using different analytical approaches.
- Data Governance and Security: Data governance and security features are crucial components of a data lakehouse, helping organizations manage access controls, enforce data policies, and ensure compliance with regulations.
- Scalability: Similar to data lakes, a data lakehouse is designed to scale horizontally, allowing organizations to handle growing volumes of data efficiently.
Prominent technologies associated with the concept of a data lakehouse include platforms like Delta Lake (databricks), Snowflake and Apache Iceberg, which provide capabilities for managing structured data within a data lake environment while incorporating ACID transactions and other features typically associated with data warehousing.
The data lakehouse concept seeks to bridge the gap between the flexibility of data lakes and the structured processing capabilities of data warehouses, offering a more comprehensive and adaptable solution for modern data management and analytics.
Limitations of Data Lakehouse:
While the data lakehouse concept addresses many challenges associated with traditional data lakes and warehouses, it also comes with its own set of limitations. These limitations highlight areas where organizations need to carefully plan and implement strategies to maximize the benefits of a data lakehouse. Data lakehouse is still an evolving technology and the current set of challenge and limitations might get addressed in coming future.
Here are some common limitations:
- Complexity of Implementation: Setting up a data lakehouse can be complex and may require significant expertise in both data engineering and data governance. The integration of different components and technologies, such as Delta Lake or Apache Iceberg, demands careful planning and execution.
- Costs: Implementing and maintaining a data lakehouse, especially in a cloud environment, can incur substantial costs. Storage costs for raw and processed data, as well as the computational resources required for analytics workloads, contribute to the overall expense.
- Data Governance Challenges: Maintaining proper data governance in a data lakehouse, including metadata management, data lineage tracking, and access controls, can be challenging. Ensuring data quality and enforcing data policies across diverse types of data require careful attention.
- Learning Curve: Teams may face a learning curve when adopting a data lakehouse architecture, especially if they are transitioning from traditional data warehousing or data lake solutions. Training and education are essential to harness the full potential of the technology.
- Performance Considerations: While a data lakehouse improves performance compared to traditional data lakes for structured data, it may not match the performance of dedicated data warehouses for certain types of queries. Organizations need to assess their specific performance requirements against the capabilities of the chosen data lakehouse solution.
- Tooling and Ecosystem Maturity: The tooling and ecosystem around data lakehouses may not be as mature or standardized as those for traditional data warehouses. Integration with existing tools, libraries, and analytics platforms may require additional development and customization.
- Potential for Data Swamp: Without proper management and governance, a data lakehouse can face challenges similar to those of a data swamp. It may accumulate redundant, outdated, or trivial (ROT) data, making it difficult for users to find relevant and valuable information.
- Evolution of Standards: As the concept of data lakehouse continues to evolve, standards and best practices may not be universally established. Organizations adopting early iterations of the technology should be prepared for potential changes in standards and adaptability requirements.
- Vendor Lock-In: Depending on the chosen platform and technologies, organizations may face potential vendor lock-in, limiting their ability to easily switch to alternative solutions or cloud providers.
Despite these limitations, a well-implemented data lakehouse can offer significant advantages in terms of flexibility, scalability, and support for diverse analytics workloads. Organizations should carefully evaluate their specific needs, consider the maturity of the technology, and invest in proper governance and management practices to mitigate these limitations effectively.
At HelicalTech we have got more than a decade of implementation in Data industry and have got experience across all the three generations ie Data Warehouse, Data Lake and Data Lakehouse as well as experience across various open source and proprietary technologies on the BI side. This includes Open source Helical Insight, Jaspersoft, Pentaho, PowerBI, Tableau, Quicksight. On the data pipeline & data lake/lakehouse side our experience includes various tools like Talend, DBT, Pentaho data integration, AWS Glue, Apache Spark, Airbyte, Airflow, Snowflake, Databricks etc.
Do reach out on nikhilesh@helicaltech.com to discuss further how Helical can help you with your data journey.
A Guide to the Modern Data Stack Evolution of Data Stack Evolution of the Modern Data Stack How Can the Modern Data Stack Evolve and Develop The Hidden Challenges of the Modern Data Stack The Reign of Modern Data Stack Unlock the Next Evolution of the Modern Data Stack What is the data stack? What is the difference between traditional data stack and modern data stack? What is the modern data stack When did the modern data stack start?