Introduction to AWS Glue
AWS Glue is a cloud-optimized ETL service. It is a cloud service that prepares data for analysis through the automated extract, transform and load (ETL) processes. It helps to organize, locate, move and perform transformations on data sets so that they can be fetched and put to use.
Glue is different from other ETL products in certain ways.
- It is serverless.
- Provides crawlers for automatic schema generation for all kinds of data sets.
- Generate scripts automatically to extract, transform and load the data.
The service can automatically find an enterprise’s structured or unstructured data when it is stored within data lakes in Amazon Simple Storage Service (S3), data warehouses in Amazon Redshift and other databases that are part of the Amazon Relational Database Service. Glue also supports MySQL, Oracle, Microsoft SQL Server and PostgreSQL databases that run on Amazon Elastic Compute Cloud (EC2) instances in an Amazon Virtual Private Cloud.
The service then profiles data in its centralized metadata catalog, which is a metadata repository for all data assets that contain details such as table definition, location, and other attributes.
To pull metadata into the Data Catalog, the service uses Glue crawlers, which scan data stores and extract schema and other attributes for later querying and analysis.
ETL Engine
After data is cataloged, it is accessible and ready for ETL jobs. AWS Glue includes an ETL script recommendation system to create Python and Spark (PySpark) code, as well as an ETL library to execute jobs.ETL code can be written via the Glue custom library, or write PySpark code via the AWS Glue Console script editor.
PySpark code or libraries can also be imported.
Schedule, orchestrate ETL jobs
AWS Glue provides scheduled, on-demand and job completion triggers. A scheduled trigger executes jobs at specified intervals, while an on-demand trigger executes when prompted by the user. With a job completion trigger, single or multiple jobs can execute when a job finishes. These jobs can trigger at the same time or sequentially, and they can also trigger from an outside service, such as AWS Lambda.
AWS Glue Platform and Components
AWS Glue uses Apache Spark as an underlying engine to process data records and scale to provide high throughput, all of which is transparent to AWS Glue users.
AWS Glue has three main components:
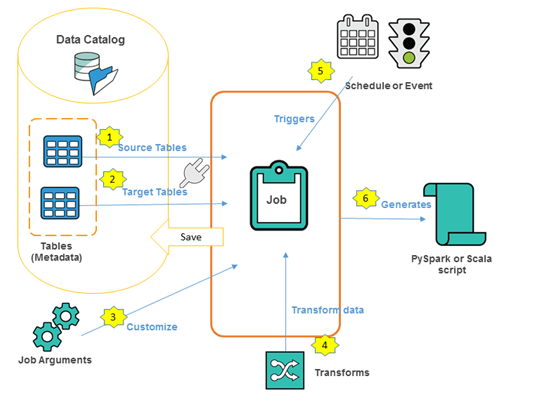
Data Catalog— A data catalog is used for storing, accessing and managing metadata information such as databases, tables, schemas, and partitions. Crawlers infer the schema/objects within data sources while setting up a connection with them and create the tables with metadata in AWS Glue Data Catalog.
ETL Engine—Once the metadata is available in the catalog, data analysts can create an ETL job by selecting the source and target data stores from the AWS Glue Data Catalog. The next step is to define an ETL job for AWS Glue to generate the required PySpark code. The code can be customized based on transformation requirements.
Scheduler—Once the ETL job is created, it can be scheduled to run on-demand, at a specific time or upon completion of another job. AWS Glue provides a flexible schedule that can even retry the failed jobs.
In case if you have any queries please get us at support@helicaltech.com
Connecting to Database from AWS Glue
Fetching AWS Glue Connection Details
Email Notification for AWS Glue Job Execution
Passing and Accessing Parameters in AWS Glue Job
How to use External Python Libraries in AWS Glue Job
CDC Capture Changes Made at Data Source
Thank You
Rajitha
Helical IT Solutions Pvt Ltd
 Best Open Source Business Intelligence Software Helical Insight Here
Best Open Source Business Intelligence Software Helical Insight Here
A Business Intelligence Framework
Best Open Source Business Intelligence Software Helical Insight is Here