Introduction
Deep learning is a subset of machine learning. There are certain specialties in which we perform machine learning, and that’s why it is called deep learning. For example, deep learning uses neural networks, which are like a simulation of the human brain. Deep learning also involves analyzing large amounts of unstructured data, unlike traditional machine learning, which typically uses structured data. This unstructured data could be fed in the form of images, video, audio, text, etc.
TensorFlow is an open-source library that the Google Brain team developed in 2012. Python is by far the most common language that TensorFlow uses. You can import the TensorFlow library into your Python environment and perform in-depth learning development.
There is a sure way in which the program gets executed. You first create nodes, which process- the data in the form of a graph. The data gets stored in the form of tensors, and the tensor data flows to various nodes.
Why Use TensorFlow?
One of TensorFlow’s best qualities is that it makes code development easy. The readily available APIs save users from rewriting some of the code that would otherwise have been time-consuming. TensorFlow speeds up the process of training a model. Additionally, the chances of errors in the program are also reduced, typically by 55 to 85 percent.
The other important aspect is TensorFlow is highly scalable. You can write your code and then make it run either on CPU, GPU, or across a cluster of these systems for the training purpose.
Generally, training the model is where a large part of the computation goes. Also, the process of training is repeated multiple times to solve any issues that may arise. This process leads to the consumption of more power, and therefore, you need a distributed computing. If you need to process large amounts of data, TensorFlow makes it easy by running the code in a distributed manner.
GPUs, or graphical processing units, have become very popular. Nvidia is one of the leaders in this space. It is good at performing mathematical computations, such as matrix multiplication, and plays a significant role in deep learning. TensorFlow also has integration with C++ and Python API, making development much faster.
What is a Tensor?
A tensor is a mathematical object represented as arrays of higher dimensions. These arrays of data with different sizes and ranks get fed as input to the neural network. These are the tensors.
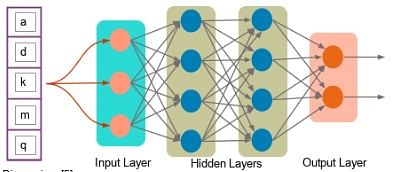
You can have arrays or vectors, which are one-dimensional, or matrices, which are two-dimensional. But tensors can be more than three, four or five-dimensional. Therefore, it helps in keeping the data very tight in one place and then performing all the analysis around that.
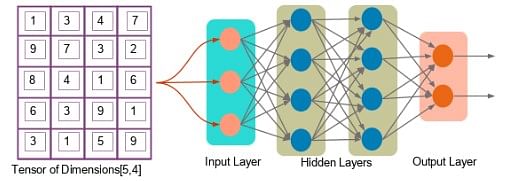
Let us look at an example of a tensor of [5,4] dimensions (two-dimensional).
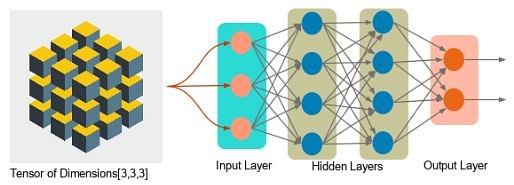
Next, you can see a tensor of dimension [3,3,3] (three-dimensional).
Tensor Rank
Tensor rank is nothing but the dimension of the tensor. It starts with zero. Zero is a scalar that doesn’t have multiple entries in it. It’s a single value.
For example, s = 10 is a tensor of rank 0 or a scalar. V = [10, 11, 12] is a tensor of rank 1 or a vector. M = [[1, 2, 3],[4, 5, 6]] is a tensor of rank 2 or a matrix. T = [[[1],[2],[3]],[[4],[5],[6]],[[7],[8],[9]]] is a tensor of rank 3 or a tensor.
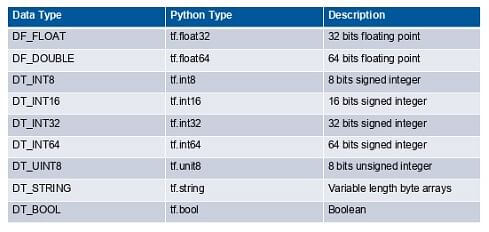
Tensor Data Type
In addition to rank and shape, tensors also have a data type. The following is a list of the data type:
Building a Computation Graph
Everything in TensorFlow is based on designing a computational graph. The graph has a network of nodes, with each node operating addition, multiplication, or evaluating some multivariate equation.
The code is written to build the graph, create a session, and execute that graph. A graph has nodes that represent mathematical operations, and an edge represents tensors. In TensorFlow, a computation is explained using a data flow graph.
Everything is an operation. Not only adding two variables but creating a variable is also an operation. Every time you assign a variable, it becomes a node. You can perform mathematical operations, such as addition and multiplication on that node.
You start by building up these nodes and executing them in a graphical format. That is how the TensorFlow program is structured.
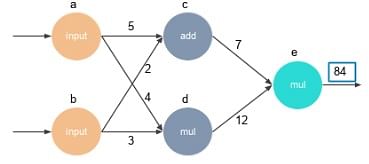
Here’s an example that depicts how a computation graph gets created. Let’s say you want to perform the following calculation: F(a,b,c) = 5(a+bc)
The three variables a, b, and c translate into three nodes within a graph, as shown.

In TensorFlow, assigning these variables is also an operation.
Step 1 is to build the graph by assigning the variables. Here, the values are: a = 4 b = 3 c = 5 Step 2 of building the graph is to multiply b and c. p = b*c Step 3 is to add ‘a’ to ‘bc.’ q = a + p Then, we need multiple q, and 5. F = 5*q
Finally, you get the result.
Here, we have six nodes. First, you define each node and then create a session to execute the node. This step, in turn, will go back and execute each of the six nodes to get those values.
Programming Elements in TensorFlow
Unlike other programming languages, TensorFlow allows you to assign data to three different data elements:
- Constants
- Variables
- Placeholders
Constants
Constants are parameters with values that do not change. We use the tf.constant() command to define a constant.
Example: a = tf.constant(2.0, tf.float32) b = tf.constant(3.0) Print(a, b)
You cannot change the values of constants during computation. Specifying the data, the constant is optional.
Variables
Variables allow us to add new trainable parameters to the graph. To define a variable, we use the tf.Variable() command and initialize them before running the graph in a session.
Example:
W = tf.Variable([.3],dtype=tf.float32) b = tf.Variable([-.3],dtype=tf.float32) x = tf.placeholder(tf.float32) linear_model = W*x+b
Placeholders
Placeholders allow us to feed data to a TensorFlow model from outside a model. It permits value to be assigned later. To define a placeholder, we use the tf.placeholder() command.
Example:
a = tf.placeholder(tf.float32) b = a*2 With tf.Session() assess: result = sess.run(b,feed_dict={a:3.0})
Print Result
The Print Result is somewhat similar to a variable but primarily used for feeding data from outside. Typically, when you perform a deep learning exercise, you cannot get all the data in one shot and store it in memory. That will become unmanageable. You will generally get data in batches.
Let’s assume you want to train your model, and you have a million images to perform this training. One of the ways to accomplish this would be to create a variable, load all the images, and analyze the results. However, this might not be the best way, as the memory might slow down or there may be performance issues.
The issue is not just storing the images. You need to perform training as well, which is an iterative process. It may need to load the images several times to train the model. It’s not just the storing of million images, but also the processing that takes up memory.
Another way of accomplishing this is by using a placeholder, where you read the data in batches. And maybe out of the million images, you get a thousand images at a time, process them and then get the next thousand and so on.
That is the idea behind the concept of a placeholder; it is primarily used to feed your model. You read data from outside and feed it to a graph using a variable name (in the example, the variable name is feed_dict).
When you’re running the session, you specify how you want to feed the data to your model.
Session
Once you create a graph, you need to execute it by calling a session or using a method called run. A session is run to evaluate the nodes, which is called the TensorFlow runtime.
You can create a session by giving the command as shown:
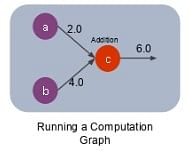
sess = tf.Session() Consider an example shown below: a = tf.constant(5.0) b = tf.constant(3.0) c = a*b # Launch Session sess = tf.Session() # Evaluate the Tensor c print(sess.run(c))
There are three nodes: a, b, and c. We create a session and run the node ‘c’ as this is where the mathematical operation is carried out, and the result is obtained.
On running the node c, first nodes a and b will get created, and then the addition will be done at node c. We will get the result ‘6’ as shown below:
Other Uses
You can build other machine learning algorithms on it as well such as decision trees or k-Nearest Neighbors. Given below is an ecosystem of TensorFlow:
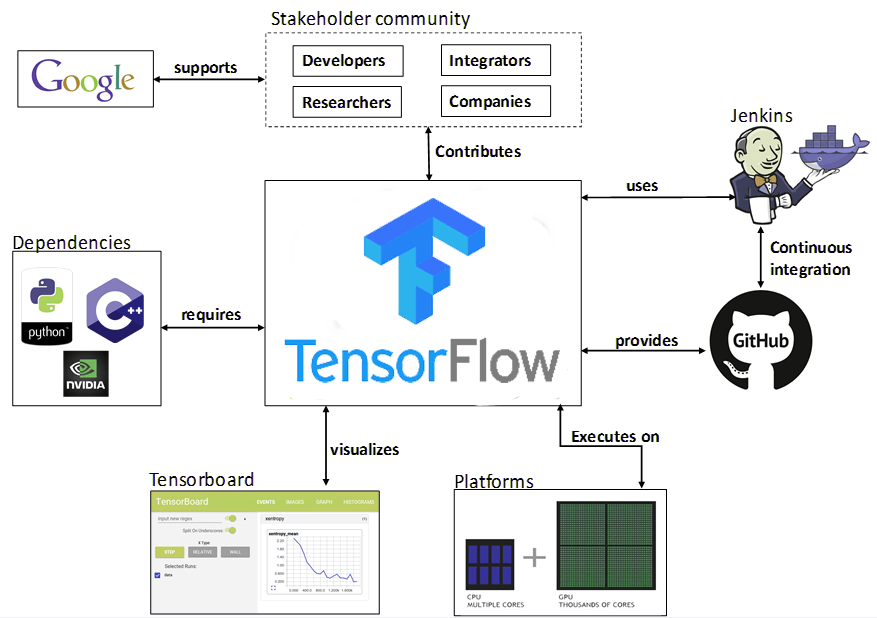
TensorFlow Tutorial — TensorFlow Ecosystem
As can be seen from the above representation, TensorFlow integrates well and has dependencies that include GPU processing, python and Cpp and you can use it integrated with container software like Docker as well.
Conclusion
TensorFlow is a great library that can be used for numerical and graphical computation of data in creating deep learning networks and is the most widely used library for various applications like Google Search, Google Translate, Google Photos, and many more.
There are numerous and amazing things that people have done using machine learning, some of which include applications relating to health care, recommendation engines for movies, music, personalized ads, and social media sentiment mining to name a few.
With these advancements in machine learning and artificial intelligence that seem mind-boggling, TensorFlow is a tool that is helping to achieve these goals.
Deep Learning Machine learning education TensorFlow in Deep Learning What algorithm is TensorFlow? What is Tensorflow | TensorFlow Introduction