A Simple yet Effective way to implement Rollback in Pentaho
What is a Rollback mechanism?
In database technologies, a rollback is an operation which returns the database to some previous state. Rollbacks are important for database integrity, because they mean that the database can be restored to a clean copy even after erroneous operations are performed. They are crucial for recovering from database server crashes; by rolling back any transaction which was active at the time of the crash, the database is restored to a consistent state .
Why do we need it?
There comes scenarios where there could be a Job failure or a database crashing at a crucial juncture , in that case going back to the previous stable state always helps and the rollback mechanism helps out in the same.
The Process:
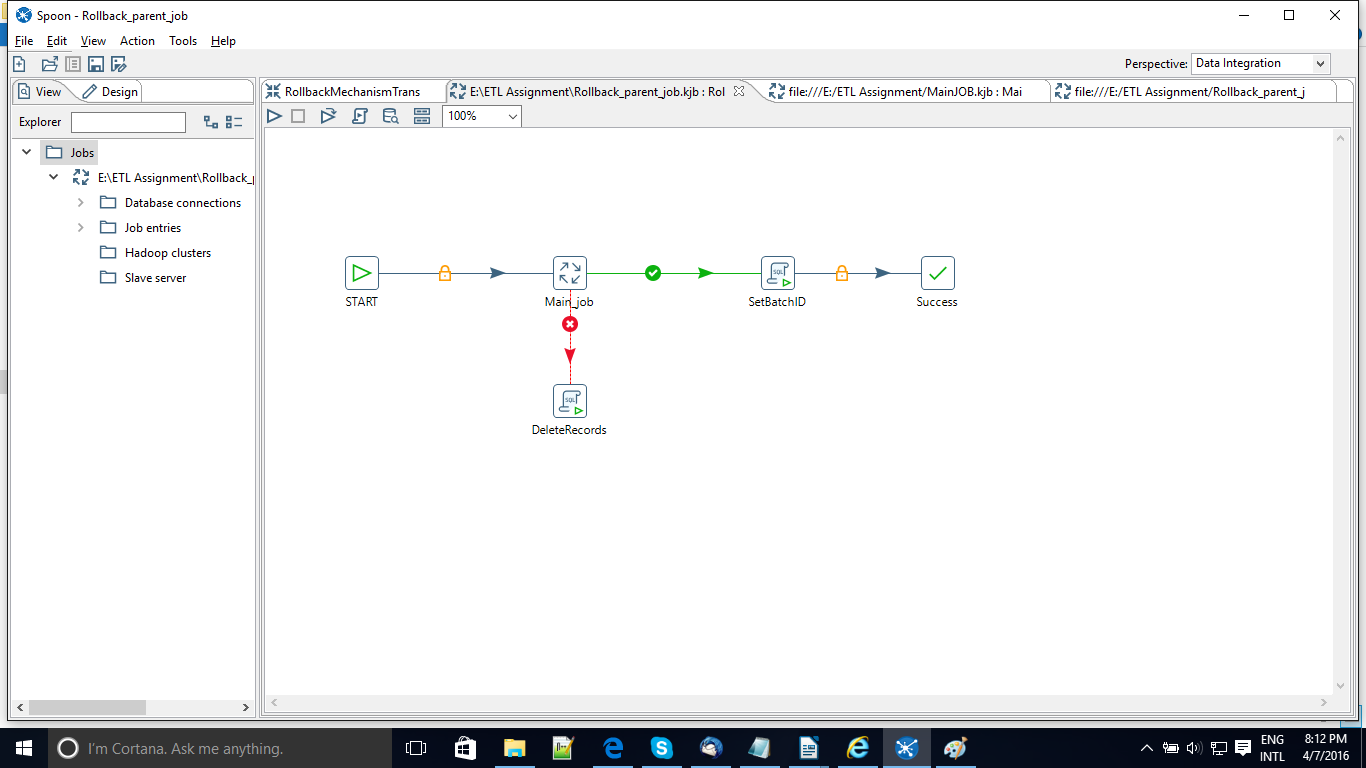
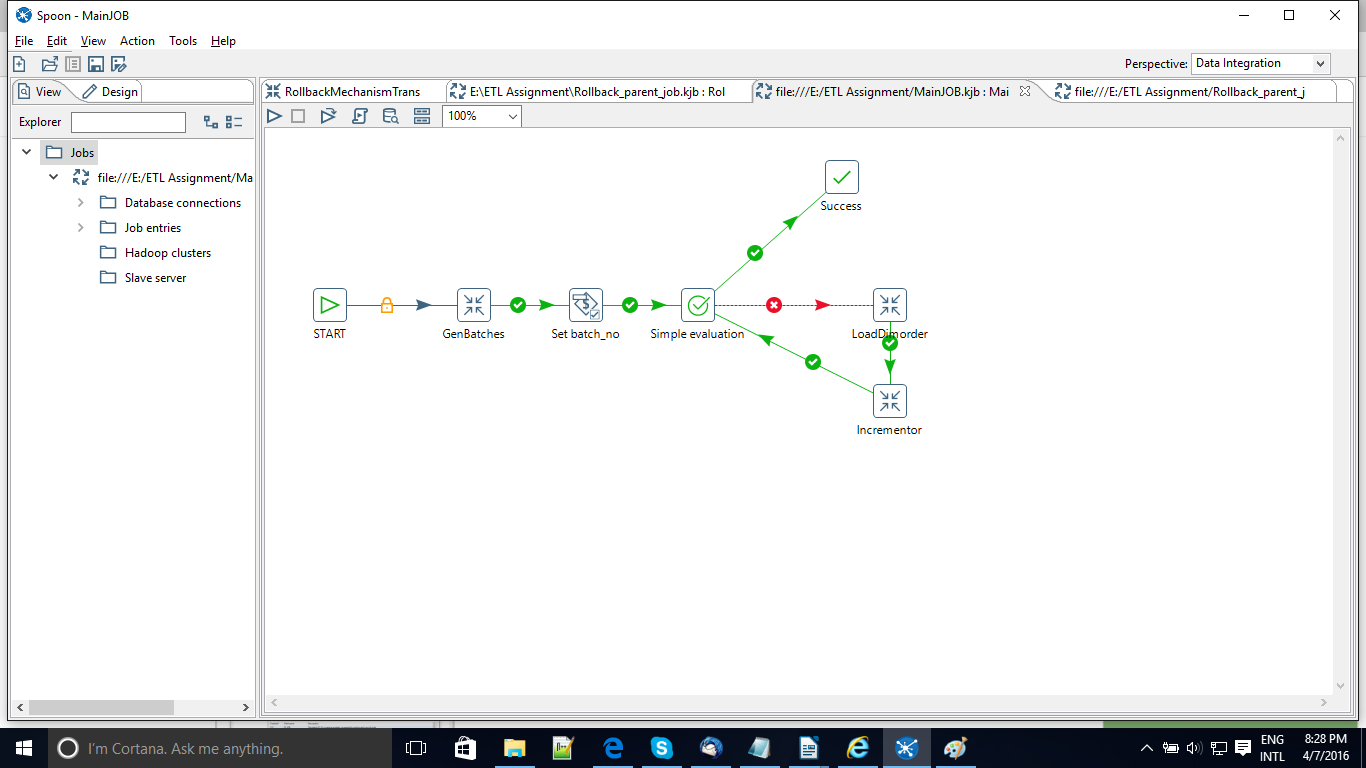
In our case we have a situation where we have a Parent job named Rollback Parent job and a subsequent job i.e Main Job under it that holds the functional part of things. The Main job follows a batchwise data loading process into the target Dim_OrderDetails. Under it we have the LoadDimOrder transformation where the data loading process happens.
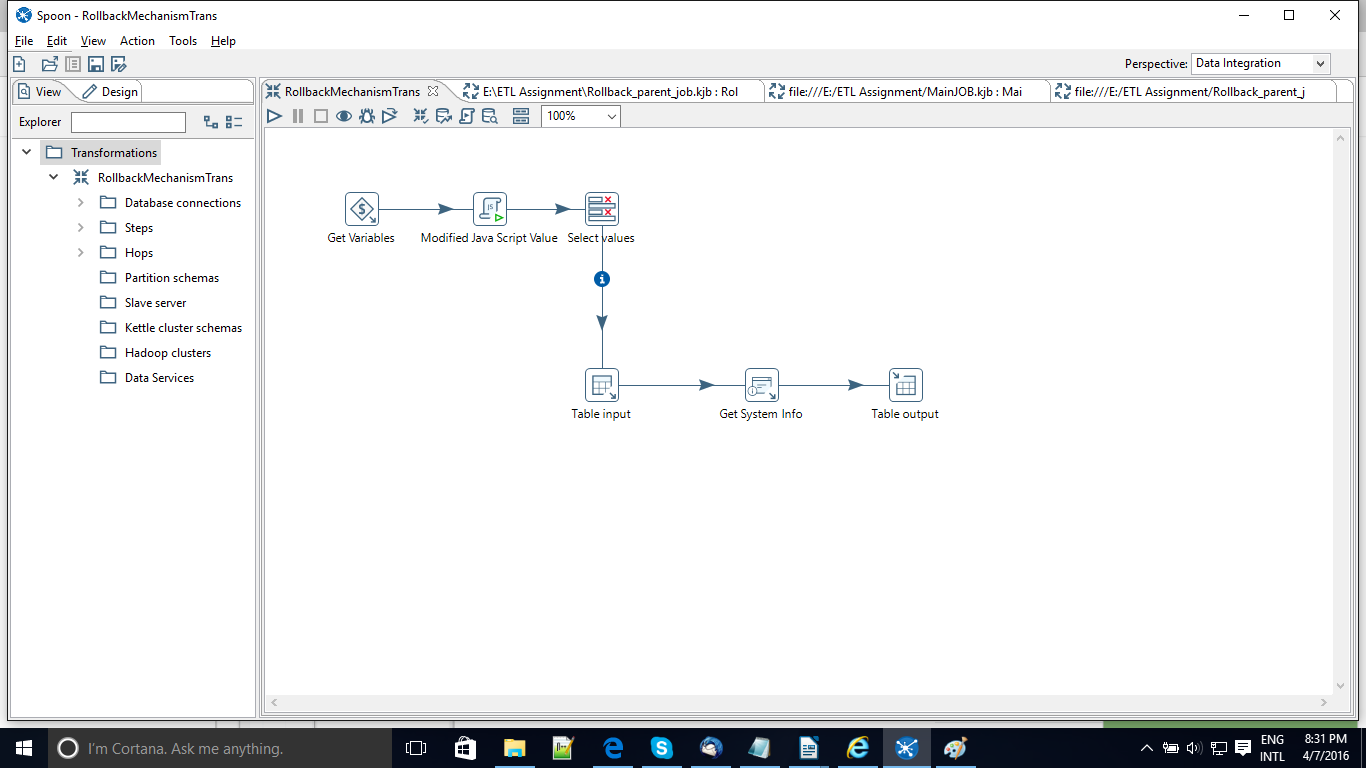
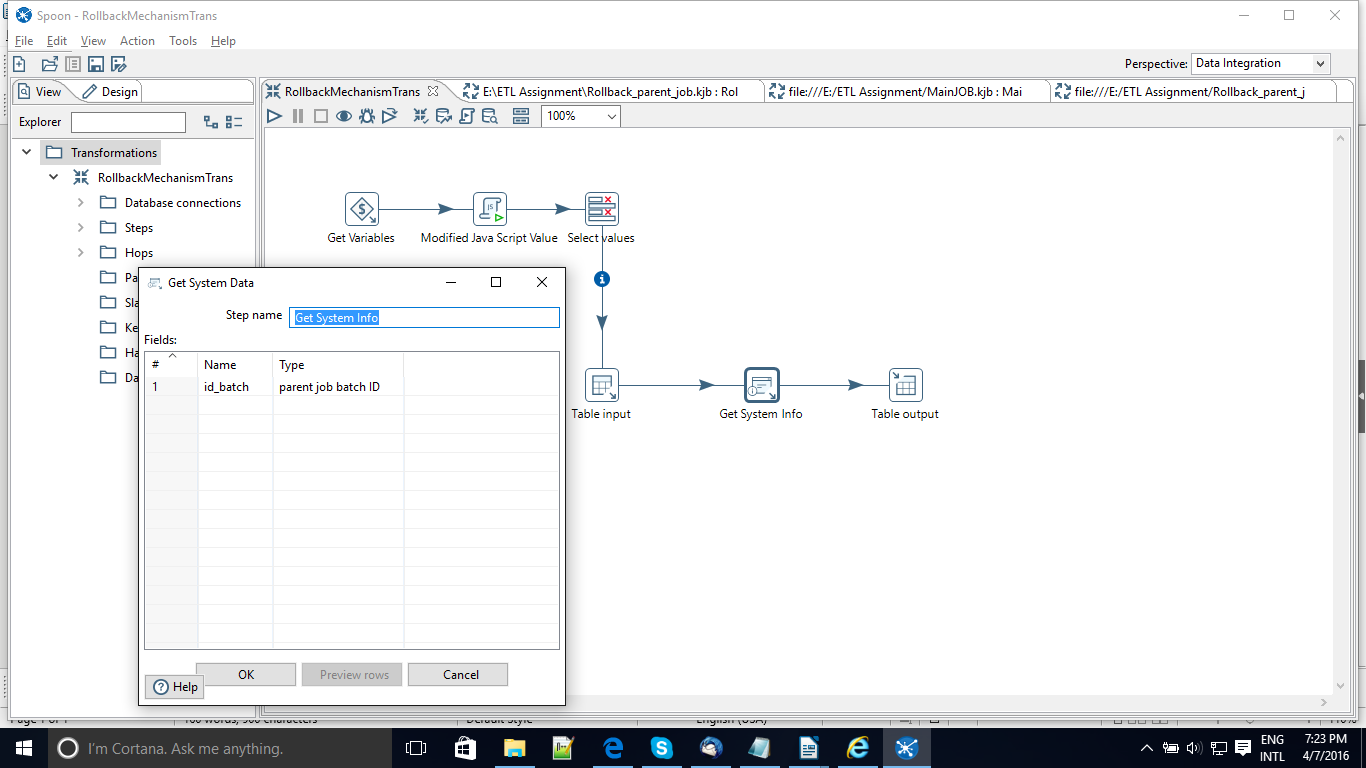
To start lets go to the main transformation i.e Rollback transformation where we are using the GetSystemInfo component which will help us in the rollback mechanism. If you go through the below screenshot we have set a new column id_job with the type as parent Job BatchID which sets the value to a constant 0. This is the same field which is used in the logging table provided by Pentaho. Below screenshot will give you an idea.The reason it sets as 0 is because we havent passed the id_job onto the transformation so it sets a default value 0.
Finally we pass this onto the Dim_orderDetails table. So now everytime a new record is pushed to the target table it sets the value for the id_job column as 0.
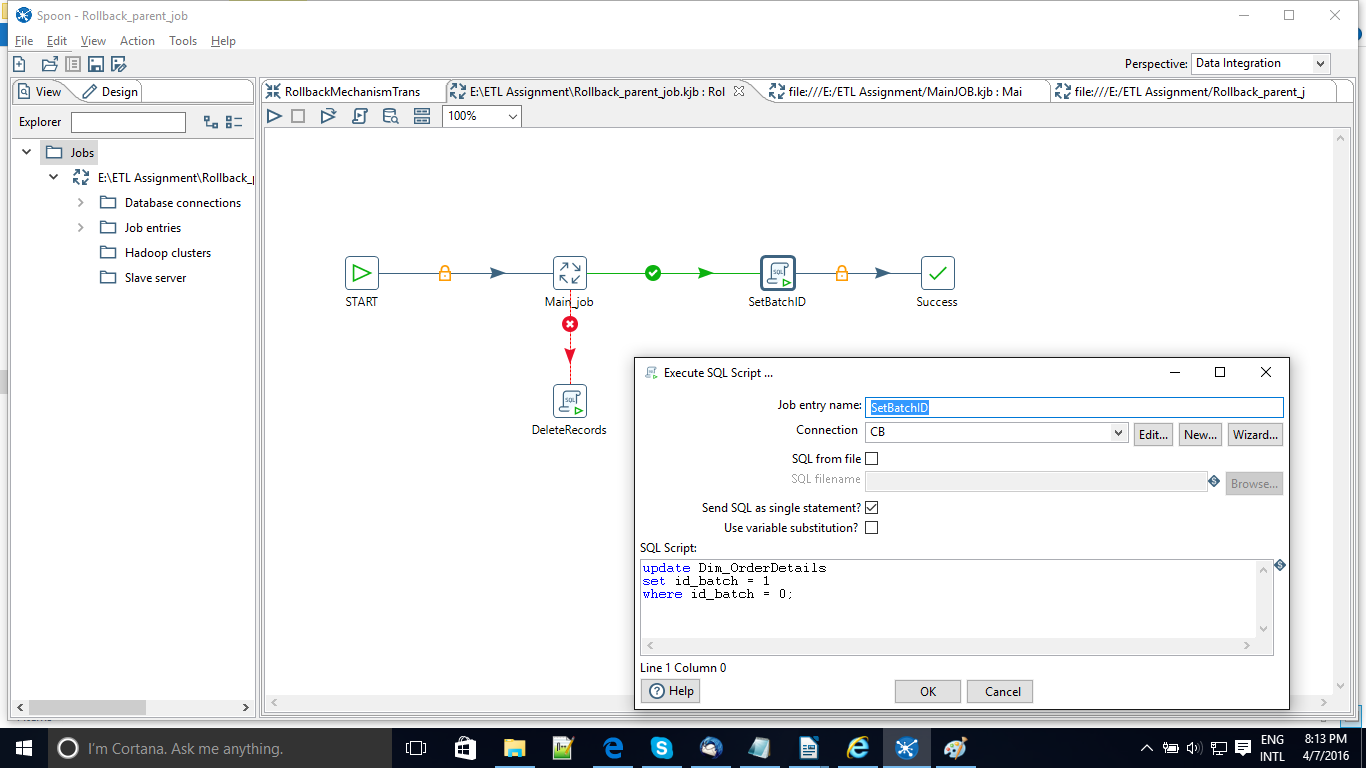
Now when you go back to the Parent Job you can see after the Main Job step we have two directed hops where one is an error handling step and the other follows the condition when the previous step runs successfully. Now when the MainJOB step runs successfully the data flow continues to the next step where all the id_batch values are set to a constant value 1. This becomes our savepoint where we know that all the perfectly loaded records are carrying the id_job value as 1.
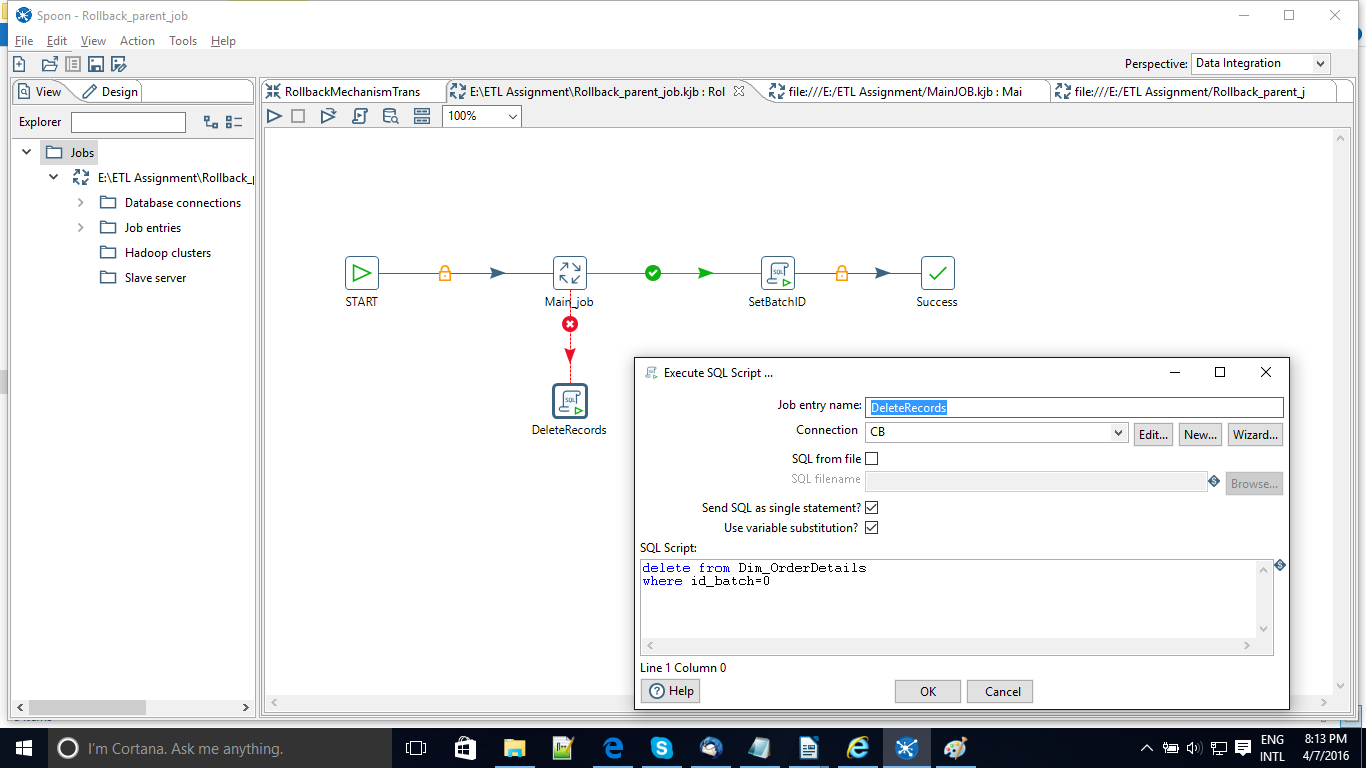
Similarly if for some reason the MainJob fails the data flow will move to the DeleteRecords step where all the latest records carrying the id_job = 0 will be deleted.
Hence the next time our job runs the previous successfully loaded records will carry the id_job as 1 and the new records will be set 0 initially so that we can handle the errors with the latest records. So this is one way to implement rollback mechanism at the ETL front.
Sayed Shakeeb Jamal

That’s not actually a Rollback, but rather a back-out.