INTRODUCTION
In this article we are going to see what is AWS glue, AWS Glue resources, and how to submit a job using pyspark.
REQUIREMENTS
To use the AWS glue we should have the following setups in our system:
1. AWS account should be created with data present in S3.
2. Apache Spark (can be downloaded at this site)
https://phoenixnap.com/kb/install-spark-on-windows-10
WHAT IS AWS Glue ?

AWS Glue is a fully managed ETL service which makes it simpler and cost-effective to categorize your data, clean it, enrich it, and move it reliably between various data stores and data streams.
ETL means Extract Transform Load, which means that the AWS extracts the data from the JDBC, S3, Redshift or any other databases and transforms it to required format and then loads it to the data warehouse.
AWS Glue ETL scripts can be coded in Python or Scala. Python scripts use a language that is an extension of the Pyspark Python dialect for extract, transform, and load (ETL) jobs.

AWS GLUE RESOURCES
Data Catalog: It stores the metadata of the actual data. If we have data in the database, we can access it through JDBC connections.The information in the Data Catalog is used to create and monitor your ETL jobs.
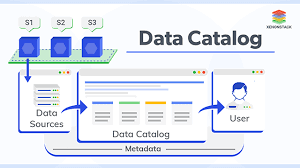
Database: It is the logical separation of the tables we will be getting.We have to create the databases in AWSGlue. Upload the files in csv format into the database.

Connections: The connections are the Data Catalog objects that stores connection information for a particular data store. We can add the connections here .

Crawlers: The crawler understands the connections and gets data from the data catalog and updates one or more tables in your Data Catalog. ETL jobs that are defined in AWS Glue use these Data Catalog tables as sources and targets.

Job: Job is the business logic which is required to perform ETL work. There are three types of jobsSpark, Streaming ETL, and Python shell. A Spark job is run in an Apache Spark environment managed by AWS Glue.
It processes data in batches. A streaming ETL job is similar to a Spark job, except that it performs ETL on data streams. We can submit the job using spark-submit or in console.

SPARK-SUBMIT USING PYSPARK
Once we have the AWS glue ready with all the requirements mentioned above we can start to submit the job.
Steps to submit a job using spark:
Step1: Create a python file based on what operation you should perform for the file present in database.
For example, Lets create a file called example.py which has code to read what is present in the file.
The below code loads the data of the csv file into the dataframe. Thus, we can perform the operations as required.

Step2: Now open the command prompt and give the command
spark-submit “location of the python file”

The output yield us the schema of the csv file as shown below,
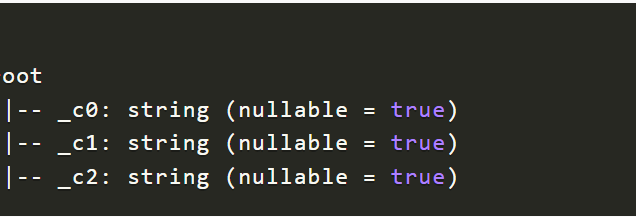
Step 3: Now we are able to access the file in the database, Thus we can perform any operations like filtering data, reading, writing and upload it using spark.
Conclusion:
The AWS Glue has certain resources which combine together to provide us the upload files in it and perform changes as per requirement. The data present in the AWS Glue can be accessed by using pyspark by submitting the job (creating ETL jobs) as explained.
Thank You
Vani Bolle
Helical IT Solutions

Best Open Source Business Intelligence Software Helical Insight is Here