Delete Duplicate Records From a Table without Primary key
To find the duplicate records in the data and delete them
Specifications: There is a table tbl1 with columns as follows

The data is as follows:

Query is to be written to find the duplicate records and delete them.
Here by Duplicate record we mean the record which is getting repeated. So the requirement is like say if there are 2 records which are exactly same what is required is to keep only 1 record of that kind.
NOTE: Id in the table tbl1 is not the primary key.
THOUGHT PROCESS REGARDING THE STATEMENT:
1. We cannot approach by using WHERE clause because in our case the whole record is same.
So this wont work.
2. ALTER IGNORE TABLE cannot be used because practically its always not possible that we have
the privileges.
3. This way we can find what is the count of records which are getting repeated (useful when we have large no of records say in thousands
QUERY : select id,count(*) from
(select * from tbl1) a
group by id;
4. One might think add another column to rank the records and to have a functionality like AUTO INCREMENT
QUERY : set @x :=0;
select a.*,@x :=@x+1 as row_cnt from tbl1 a
The above query will give us another column that is row_cnt.
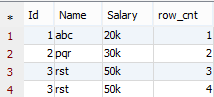
Now after this if fire a delete query based on row_cnt. It will generate error because actually we are not adding any column like row_cnt in the table, its just a virtual column(display purpose) cant perform operations on it.
5. Another way in which one might think is to create a temporary table with an additional col of duid which works like auto increment and dump all data from original table into that TEMPORARY table
QUERY: create TEMPORARY table dup
(did varchar(20),
dname varchar(20),
dsalary varchar(20),
duid integer);
For inserting into dup
QUERY : insert into dup
select id,name,salary,@x:= @x+1 from tbl1, (select @x := 0) d ;
After that one might think of firing the delete command so even if we do it both the records with same id will be deleted we dont want do that we want 1 record.
CORRECT WAY:
1. Creating a table tbl1
2. Getting the distinct records from tbl1(main table)
QUERY : SELECT distinct id, name,salary FROM tbl1
3. Creating another table tmp_tbl1(second table)
QUERY : create table tmp_tbl1(id varchar(3),name varchar(30),salary varchar(10))
4. Inserting distinct records from tbl1 to tmp_tbl1
QUERY : INSERT INTO tmp_tbl1 (SELECT distinct id, name,salary FROM tbl1)
5. Truncate the main table i.e tbl1
QUERY : truncate table tbl1
6. Inserting the distinct records from tmp_tbl1( second table) to tbl1(main table)
QUERY : INSERT INTO tbl1(SELECT * FROM tmp_tbl1)
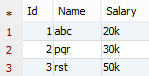
7. QUERY : select * from tbl1

Best Open Source Business Intelligence Software Helical Insight is Here