Introduction
In this blog we are going to cover how to implement Data Lake on AWS.
AWS cloud technologies enable us to build scalable data lakes that can store petabytes of structured and unstructured data , data ingestion and data processing pipelines to ingest, clean, transform the data as well as provides tools to query/analyze the data. Depending on the nature of the data, size, analysis requirements, we can use the various AWS products to build our data analytics architecture. Below is a sample architecture that gives an idea of the various layers / components that a typical data lake architecture would comprise of.
Architecture data lake on AWS
This diagram shows a layered architecture which comprises of 6 Layers –
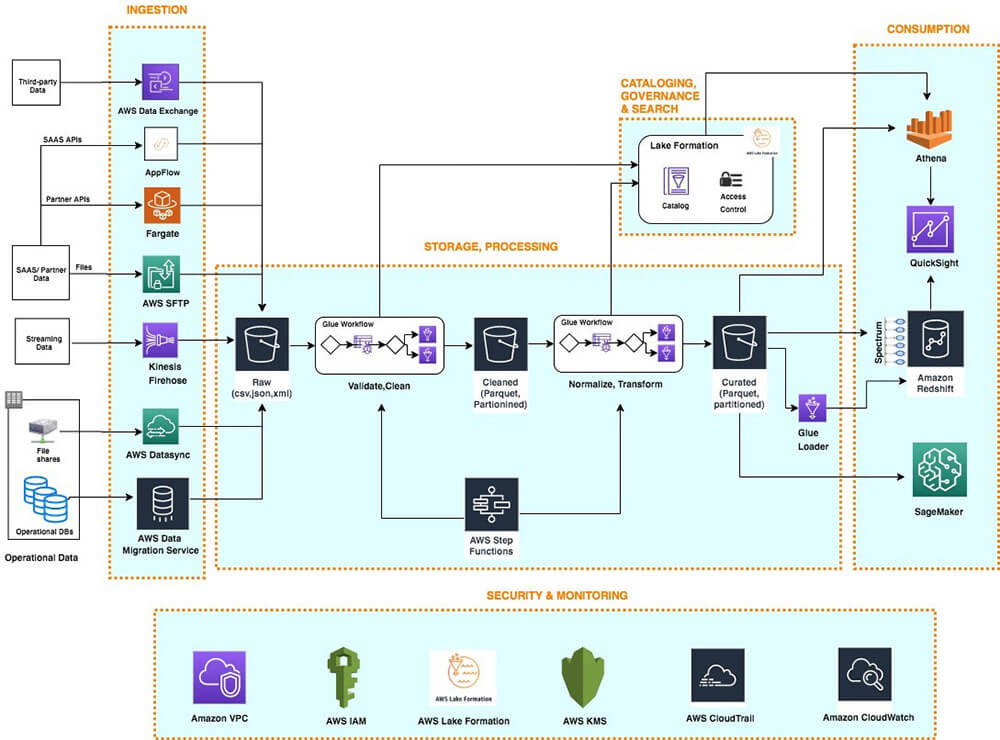
Ingestion – This layer is responsible for ingesting data into the various data storage targets which form the data lake. The storages used could be object store which stores raw files or databases. Ingestion layer has the capability to connect to diverse data sources and can ingest batch or streaming data into the lake.
Storage – This layer is responsible for storing the raw data as well as processed data. It should be scalable as well as cost effective to allow us to store vast quantities of data. It also has security, high availability, data archival and backup capabilities.
Catalog – This layer is responsible to store all the metadata related to data present in the data lake. It also provides search capabilites to search for data in the lake. The metadata information could be technical like the schema, data types, size etc or business information like data owner.
The catalogs also allows auto-discovery and updation of metadata for any new data sets.It also has versioning capabilities.
Processing – This layer is responsible for data cleansing and also data transformation. These layer has the data processing pipelines and the means to orchestrate the data flow. It has mechanisms for auditing , reconciliation of data at various stages in the pipeline.
Consumption – This is the layer which provides tools that support analysis methods, including SQL, batch analytics, BI dashboards, reporting, and ML.
Security and Monitoring – This layer ensures security to the various components of all layers in the data analytics architecture. It has means for authentication, authorization, encryption, monitoring, logging, alerts.
AWS Services Used
Below are some of the services used by the above architecture in its various layers as can be seen in the diagram.
AWS App Flow – This service could be used in the ingestion layer to connect to supported SAAS platforms and pull data into the data lake. It is secure, allows transfer of data at mass scale and can also be configured to do some quick validations and cleanup
Amazon Kinesis Data Firehose – This service allows ingestion of real-time data streams into the data lake. It could load the data into object store like Amozon S3 or directly into Amazon Redshift. It allows you to even convert the raw stream data into parquet format and partition without building a data processing pipeline.
AWS Datasync – This could be used in your ingestion layer to migrate data from your on-premise to your AWS storage like S3. Like if you have data in on-premise Hadoop Distributed File Systems (HDFS), Network File System (NFS) shares and other such supported object stores.
AWS S3 – This is can be used as storage for your data lake raw data. Data can be ingested from various data sources as files into S3. S3 integrates well with different AWS services which can fall in our processing, storage, ingestion, catalog as well as consumption layers. It is a preferred service for data lake storage.
AWS Redshift – This can be used in your storage layer to store processed data, it’s a cluster based warehouse service. It can run thousands of high performant queries in parallel which can power your dashboards and other analytics. Amazon Redshift provides native integration with Amazon S3 in the storage layer, Lake Formation catalog, and AWS services in the security and monitoring layer.
AWS Glue – This service can be used in your processing layer to doing data integration tasks, including extraction, cleaning, normalization, combining, loading, and running scalable ETL workflows. AWS Glue DataBrew can also be used by Data analysts and data scientists can use to visually clean, and normalize data without writing code. This helps fasten the data to insights process. It also allows Python or Spark code for custom logic. The other AWS services which can be used along with Glue for data pipelines and orchestration are AWS Lambda and AWS Step Functions.
AWS Lake Formation – This service provides a scalable, serverless alternative, called blueprints, to ingest data from AWS native or on-premises database sources into the landing zone in the data lake. You can define a template blueprint with source , target schema information, schedule requirements and it auto-generates an AWS Glue workflow.
This also provides a catalog which can store techical and business attributes of your data-sets. Also provides data lake administrator a central place to define data permissions for the various data-sets for user, user groups.
AWS Quicksight – This is a BI Tool from AWS can easily connect to the data in your lake and build databoards, visuals and also offers some ML insights.
If you are looking for Data Lake implementation on top of AWS (or other vendors) please reach out to us. We can show you some of our past work on Data Lake implementation, explain the pros and cons of various architecture (from technology as well as costing point of view) as well as help you with the implementation as well.
Reach out to us on nikhilesh@helicaltech.com for more information.
A Guide to Build your Data Lake in AWS AWS Data Lake Architecture Build your data lake on Amazon S3 Building a Data Lake on AWS Building Your Data Lake on AWS Data Lake Formation on AWS Getting started with AWS Lake Formation How do I create a data lake in AWS S3