Python extension modules and libraries can be used with AWS Glue ETL scripts as long as they are written in pure Python.
Python libraries used in the current Job:
-
Libraries – Pg8000
Zipping Libraries for Inclusion
The libraries to be used in the development in an AWS Glue job should be packaged in a .zip archive(for Spark Jobs) and .egg(for Python Shell Jobs).
If a library consists of a single Python module in one .py file, it can be used directly instead of using a zip archive.
Make data easy with Helical Insight.
Helical Insight is world’s best open source business intelligence tool.
Loading Python libraries into AWS Glue job
The libraries are imported in different ways in AWS Glue Spark job and AWS Glue Python Shell job.
-
Importing Python Libraries into AWS Glue Spark Job(.Zip archive) :
The libraries should be packaged in .zip archive.
- Load the zip file of the libraries into s3.
- Open the job on which the external libraries are to be used.
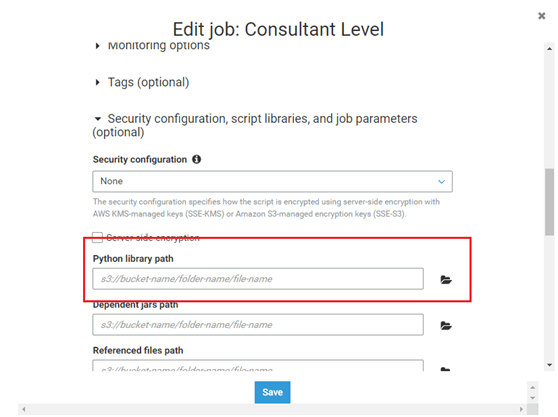
- Click on Action and Edit Job.
- Click on Security configuration, script libraries, and job parameters (optional) and in Python Library Path browse for the zip file in S3 and click save.
- Open the job and import the packages in the following format
- Prefix the user-defined name from the above step when a method is called from the package.
from package import module as myname
Example : from pg8000 import pg8000 as pg
Example : pg.connect(…) ==> connect is a method in the library.

The above steps works while working with AWS glue Spark job. To implement the same in Python Shell, an .egg file is used instead of .zip.
-
Importing Python Libraries into AWS Glue Python Shell Job(.egg file)
Libraries should be packaged in .egg file.
Make data easy with Helical Insight.
Helical Insight is world’s best open source business intelligence tool.
Creating .egg file of the libraries to be used
- Create a new folder and put the libraries to be used inside it.
- Then create a setup.py file in the parent directory with the following contents:
- To create .egg, you’ll need to do the following from the command line:
- This will generate three new folders:
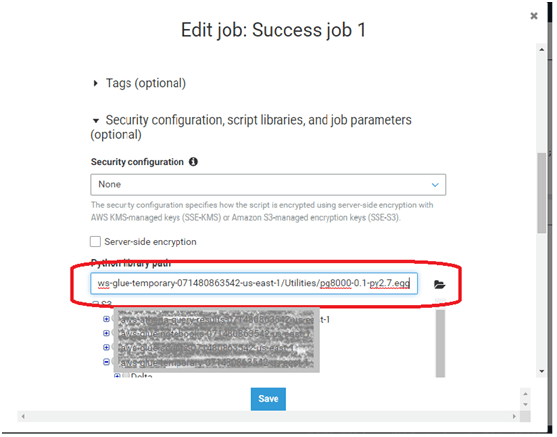
- Load the .egg file of the libraries into s3.
- This .egg file is used instead of a .zip file in the Job properties.
from setuptools import setup, find_packages
setup(
name = "pg8000",
version = "0.1",
packages = [‘pg8000’]
)
Note: If there are multiple libraries to be archived as .egg, then the folder names of the libraries are to be mentioned in the packages in an array separated by a comma.
Example: packages = [‘libraries’,’comma’,’separated’]
python setup.py bdist_egg
Build, Dist and foldername-0.1-py2.7.egg -> 2.7 is the version of the python in which the command which creates the .egg is executed.
In case if you have any queries please get us at support@helicaltech.com
Thank You
Rajitha
Helical IT Solutions Pvt Ltd

Best Open Source Business Intelligence Software Helical Insight Here
A Business Intelligence Framework
Best Open Source Business Intelligence Software Helical Insight is Here
Hi Team,
Thanks for the article. I am getting this error. ModuleNotFoundError ‘pg8000’ any idea?
Also if you can share the library or the .zip file that you have used